출처: https://dbjh.tistory.com/77
https://chanho0912.tistory.com/25
https://www.youtube.com/watch?v=4CRpndN3tP0
https://www.youtube.com/watch?v=myS_Pt4uRVs&list=PLOSNUO27qFbvzGd3yWbHISxHctPRKkctO&index=1
JPA란? 자바진영의 ORM 표준 API임(이 말이 결코 사전적이라고 느껴지면 안된다)

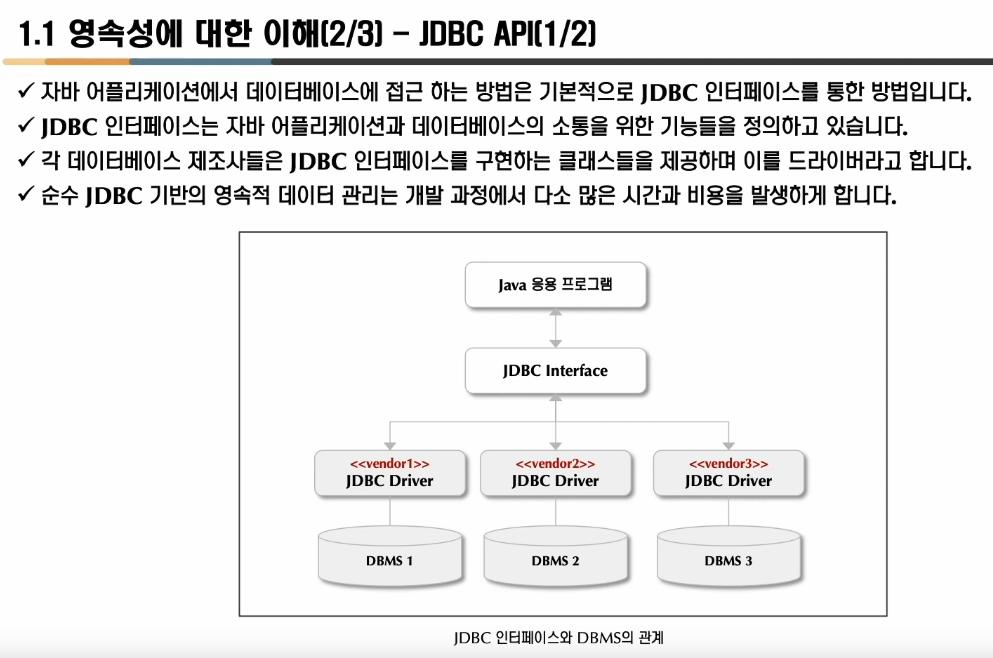
아...드라이버가 곧 클래스다!!!!!


JPA(ORM)은 나의 하인이다. CRUD의 단순하고 반복적인 쿼리작성 작업을 모두 대신하고 기계적으로 생성되는 테이블을 자동생성해 주기 때문이다.
1. JPA는 JAVA Persistence API이다.
2. JPA는 ORM기술이다.
3. JPA는 반복적인 CRUD작업을 생략하게 해준다.
4. JPA는 영속성 컨텍스트를 가지고 있다.
5. JPA는 DB와 OOP의 불일치성을 해결하기 위한 방법론을 제공한다(DB는 객체의 저장이 불가능하므로)
6. JPA는 OOP의 관점에서 모델링 할수 있게 해준다(상속, 콤포지션, 연관관계)
7. JPA는 방언처리가 용이하여 Migration하기 좋다. 유지보수에도 좋음
1. JPA는 JAVA Persistence API이다 ==>> 자바 프로그램에서 생성된 데이터를 DBMS에 영구히 저장될수 있도록 해주는 API(Java Persistence API)이다.
여기서의 Persistence는 영속성을 의미한다. 여기서 영속성이란 무슨말일까?

영속성이란? 데이터를 영구적으로 저장해주는 성질. 예를들면 파일이나 db에 넣어 영구적으로 저장함. context란? 모든 정보를 가지고 있는 것. 내가 상태패턴 배우면서 지겹게 했던 그 문맥(context) 클래스의 의미를 말하는 것임.
기본적으로 JPA는 인터페이스의 모음이면서 객체지향 언어인 JAVA와 Database 사이의 패러다임 불일치를 해결하기 위해서 도입된 규약임.
(여기서 잠깐! API와 프로토콜의 차이점은 무엇일까? 둘다 어떤 규칙, 약속인데? API는 상하관계가 존재하는 약속이며 프로토콜은 동등한 관계에서 존재하는 약속이다. from. https://www.youtube.com/watch?v=ajZIPOv31yE )
--------------------------------------------------------------------------------------------------------------------------------------------------------------
ORM이란? Object Relational Mapping의 준말로 자바의 객체를 통해 관계형DB와 mapping하는 방법론. 즉 자바의 클래스안의 멤버변수를 DB의 테이블의 각 속성들과 mapping하는 방법론으로 mapping의 방식을 표현한 것이 JPA인터페이스! 이 인터페이스의 형식을 지키면서 자바에서 클래스를 만들고 실행하면 DB의 테이블이 자동으로 생성되게 하는 기법이 바로 ORM이다!!!
즉, 2. JPA는 ORM기술이다 ==>> JPA란 ORM이라는 클래스를 테이블로 바꾸어주는 기술의 표준으로 사용되는 인터페이스 모음임.
DB로부터 가져오는 데이터타입을 타입을 자바의 Object로 변경하는 작업은 단순노가다임. 예를들어 DB로부터 데이터를 가져오거나 DB에 데이터를 저장하는 작업에 관여하는 쿼리는 매우 한정적임. 이런 간단한 CRUD작업을 생략하게끔 도와주는 것이 JPA라는 API이다. DB로부터 데이터를 받고 그것으로 부터 JAVA 객체를 만들고 연결되어있었던 세션과 Connection을 끊는 이 모든 작업을 함수하나로 제공해 줍니다. ==>>
즉, 3. JPA(의 함수만 사용하면)는 반복적인 CRUD작업을 생략하게 해주는 것입니다.
JPA는 영속성 컨텍스트를 가지고 있다.
컨텍스트? ==>>문맥 ==>>어떠한 대상의 컨텍스트라 하면 그 대상에 대한 모든 정보를 의미.
프로그래밍 관련 책을 보면 컨텍스트를 넘겨준다는 말이 있습니다. 이 말은 대상 데이터에 대한 모든 정보를 넘겨준다는 것을 의미합니다.
JPA는 영속성 컨텍스트(context)를 가지고 있다? JPA는 자바와 DB사이에 오고가는 모든 정보, 상태를 영구히 가지고 있다는 말. JPA의 데이터와 DB의 데이터는 동기화 되어있기 때문에 JPA가 가지고 있는 데이터를 삭제하면 DB의 관련 데이터가 삭제됨. 자바에서 SELECT요청하는 것은 엄밀히 DB에 그런 쿼리를 보내는 것이 아니라 JPA에 쿼리를 보내는 것임. 만약 자바에서 DB에 어떤 데이터를 요청해서 변경하였다면 그 해당 같은 데이터를 가지고 있는 JP의 그 데이터도 같이 변함. 그후 DB에 COMMIT하여 그 변경된 데이터를 밀어넣으면 DB의 해당데이터도 변하게 되는것. 즉 이때 DB에서 발생하게 되는 일은 INSERT가 아닌 UPDATE임.


위와 같이 DB에서 데이터를 뽑아오면 id=2, name=공필성, teamId=1 이라는 것을 알수 있지만 teamId가 1이라는 것을 그대로 사용자에게 알릴수는 없는 것이다. 왜냐하면 teamId=1라는 것은 시스템 상의 정보이므로 이것을 사용자가 1번팀이 어느팀인지 알수 없기 때문이다. 즉, 웹브라우저에 정보를 뿌릴때 2번 공필성 teamId=1이라고 뿌릴수는 없는 것이다. 따라서 정상적으로 정보를 뽑아주기 위해서는 teamId=1로부터 team테이블을 다시 Select하여 팀의 이름을 얻어오거나 테이블 join을 걸어주어야 한다. 즉 두번의 select를 하든가 join을 해주어야 한다. 하지만 실제 자바에서는 이렇게 하지 않아도 됩니다. 왜냐하면 자바는 원시타입만이 아닌 아래와 같이객체타입Object로 대상을 저장할 수 있기 때문입니다.

하지만 이렇게 만들게 되면 데이터베이스의 Player테이블과 자바의 Player클래스간의 형식적인 불일치가 발생합니다. 이러한 불일치를 ORM이라는 기술이 해결해 주는 것입니다. 즉 ORM 기술을 사용(Mapping기술)하면 모델을 만들때 자바가 주도권을 지게 되는 모델을 만들수 있습니다. 그리고 이렇게 객체타입이 포함되어있는 데이터(Player)를 DB에 Insert하거나 Select할때 JPA 자동으로 데이터를 mapping하여 데이터를 쏙 넣어주게 됩니다. 자바에서 프로그래밍 할때는 저장할 때 객체를 사용하고 객체가 포함된 Player 객체를 DB에 넣을 때는 JPA가 자동으로 team객체를 foreign key로 mapping시켜 넣어주게 되는 것(Mapping 기술)입니다.
즉, 5. JPA는 DB와 OOP의 불일치성을 해결하기 위한 방법론(like mapping)을 제공한다(DB는 객체의 저장이 불가능하므로)? 자바의 객체를 DB에 저장할때 JPA가 객체대신 foreign key를 생성하여 테이블에 저장해줌.
JPA는 DB를 만들고 거기서 만들어진 테이블을 통해서 자바의 CLASS를 모델링 하는 순서가 아닌 자바의 CLASS로부터 자동생성하여 DB의 테이블을 만듭니다(ORM기술). 즉 아래와 같은 순서로 만들어짐.
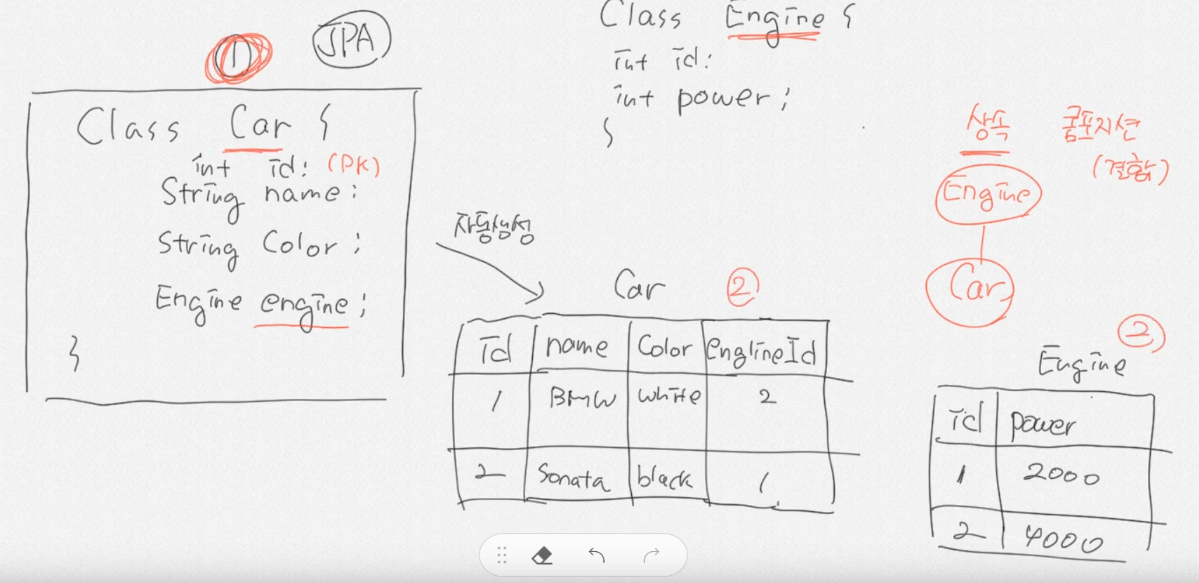
즉, JPA를 통해 1(Class Car)과 같은 Object를 통해 2(Car, Engine)와 같은 테이블이 자동생성되는 것입니다(JPA가 OOP의 관점에서 모델링 할수 있게 해주고 있음. 왜? Car이 포함관계(콤포지션)로 가지고 있는 Engine클래스를 별도의 다른 Engine테이블로 만들고 Car테이블은 EngineId라는 foreign key를 만듦. 즉, 6. JPA는 OOP의 관점에서 모델링 할수 있게 해준다(상속, 콤포지션, 연관관계)
그리고 만약 아래와 같이 자바의 클래스가 어떤 다른 클래스를 상속하게 된다면 된다면(아래에서는 EntityDate)


기존테이블을 확장하여 테이블에 createDate, updateDate라는 정보가 추가되는 형태가 된다. 즉, 6. JPA는 OOP의 관점에서 모델링 할수 있게 해준다(상속, 콤포지션, 연관관계)

상속, 콤포지션(포함관계)는 위와 같고 연관관계에 관해서는 나중에 코드로 설명함. JPA의 연관관계는 클래스를 만든후 어노테이션 키워드를 사용합니다.
7. JPA는 방언처리가 용이하여 Migration하기 좋다. 유지보수에도 좋음
방언처리가 좋다는 것은 JPA가 다양한 종류의 DB를 지원한다는 것입니다. 오라클,마리아, MySQL등등.. 따라서 우리는 JPA내에 특정 DB를 정해놓고 사용하는 것이 아닌 추상화 객체(느슨한 결합)를 포함관계로두고 사용합니다. 즉 JPA가 방언처리가 용이하는 말은 JPA가 느슨한 결합을 할수 있다는 뜻임
즉, 7.JPA는 느슨한 결합을 가질수있어 방언처리가 용이함. 이는 Migration, 유지보수 하기 좋다는 이점이 있음.
영속성 컨텍스트란?
영속성(persistency)이란 데이터를 영구적으로 저장하는 것을 의미합니다.
따라서 영속성 컨텍스트란 직역하자면 데이터에 대한 모든 정보로 해석될 수 있습니다.
기본적으로 JPA는 객체지향 언어인 JAVA와 Database 사이의 패러다임 불일치를 해결하기 위해서 도입된 규약입니다.
해당 내용을 기억하면서 본 포스팅을 이해하시면 좋을 것 같습니다.
만약에 저희가 Spring framework를 사용하여 웹 개발을 진행하고 있다고 가정해보겠습니다.
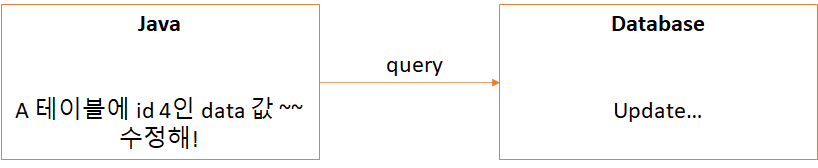
저희는 database에서 특정 id값을 갖는 데이터를 수정해달라는 요청을 받으면, database에 update 쿼리를 보내 수정을 진행하고 싶습니다.
하지만 위 그림처럼 진행하게 되면 크게 두 가지의 문제점이 있습니다.
1. 객체로 되어있는 Java의 코드를 바로 Database에 적용할 수 없습니다.
2. Database에 직접적으로 Update를 진행하게 되면 수정 중 오류가 발생하였을 때 데이터베이스의 정보가 원하는 방향으로 모두 수정이 이루어지지 않거나, Database의 정보들이 손상될 수 있습니다.
1번 문제를 해결하기 위해 저희는 JPA라는 규약을 사용합니다.

이제 2번 문제를 해결하기 위해 JPA는 영속성 콘텍스트를 이용합니다.
저희가 Service에서 update문을 수행하는 코드를 간단하게 나타내어보겠습니다.
@Transactional
public Long update(Long id, CommentUpdateDto commentUpdateDto, User user){
Comment comment = commentRepository.findById(id).orElse(null);
if(comment == null)
return ErrorCodes.NOT_EXIST;
else if(!comment.getUser().getId().equals(user.getId()))
return ErrorCodes.NOT_SAME_USER;
comment.update(commentUpdateDto.getComment());
return id;
}
해당 코드의 로직은 다음과 같습니다.
1. commentRepository에서 우리가 보낸 id와 일치하는 comment 데이터를 가져온다.
2. 해당 comment가 null값이 아닌지, 그리고 해당 comment의 작성자가 현재 요청을 보낸 user와 일치하는지 확인한다.
3. comment를 수정한다.
저희는 update 쿼리를 생성하지 않았는데, 해당 함수로 database에 업데이트를 진행할 수 있습니다.
그 과정을 한번 살펴볼게요.
1. 저희는 commentRepository에서 원하는 comment를 찾아옵니다.

해당 comment를 찾았으면 Persistence Context에 1차 캐시에 해당 Comment를 가져오고 이를 Java program에 넘겨줍니다.
당연하게도 이 시점에는 1차 캐시에 존재하는 Comment Object와 Database에 존재하는 Comment Object가 같습니다.
2. 반환받은 Comment Object의 데이터를 저희가 원하는 데이터와 비교합니다. 오류가 없으면 3번에서 실제 값을 수정합니다.
영속성이란 데이터를 일치시킴을 의미합니다. 저희가 Java 프로그램에서 해당 값을 수정하면 영속성 컨텍스트에서 보관하고 있는 Comment Object도 저희가 수정한 값으로 변경되게 됩니다.
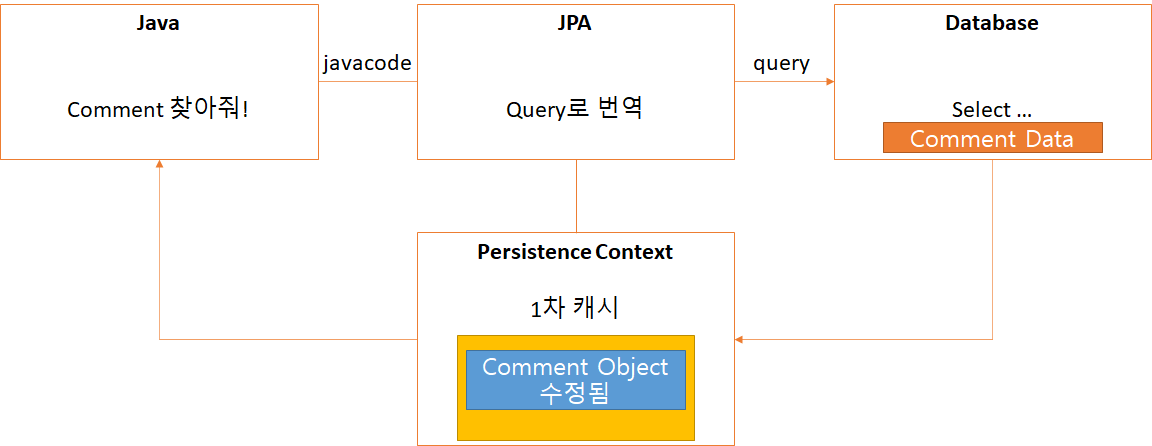
이제 이렇게 되면 Database의 데이터와 Persistence Context가 가지고 있는 data가 달라지게 됩니다.
@Transactional은 스프링 AOP전략에 따라서 해당 코드의 실행이 마무리될 때 자동적으로 commit을 진행해 줍니다. commit이 진행될 때 수정된 Object와 database의 데이터를 각각 비교하여 다른 부분을 모두 update를 해줍니다.

간략하게 작동 순서에 대해 알아보았습니다.
그럼 이제 내부적으로 어떻게 동작하는지 조금 자세하게 알아보겠습니다.
JPA는 앱 실행과 동시에 한 DB당 하나의 EntityManagerFactory를 생성합니다.
WAS가 종료되는 시점에 EntityManagerFactory는 사라집니다.
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("xxx");
entityManagerFactory.close();
이 EntityManagerFactory는 Transaction 요청이 하나 들어올 때마다 하나의 EntityManger를 생성합니다.
즉 고객의 요청이 들어오면 -> 하나의 스레드를 생성하여 EntityManager를 만들고 -> Transaction이 종료되면 해당 스레드를 종료합니다.
EntityManger의 Transaction은 다음과 같이 실행됩니다.
EntityTransaction trans = entityManager.getTransaction();
trans.begin();
trans.commit();
trans.rollback();
...
transaction이 시작되고, 해당 변경사항에 이상이 없으면 commit, 무언가 오류가 발견되면 rollback을 진행합니다.
영속성 컨텍스트의 생명주기
- 비영속(new/transient): 영속성 컨텍스트와 전혀 관계가 없는 상태
- 영속(managed): 영속성 컨텍스트에 저장된 상태
- 준영속(detached): 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제(removed): 삭제된 상태
즉 처음에 객체가 생성된 상태 -> 비영속
영속성 컨텍스트에 데이터가 저장된 상태 -> 영속
영속성 컨텍스트에 저장된 데이터가 분리된 상태 -> 준영속
마지막으로 삭제된 상태 -> 삭제
로 이해하시면 될 것 같습니다.
EntityManager entityManager = new EntityManager();
TestClass testClass = new TestClass();
// 비영속
entityManager.persist(testClass);
// 영속
entityManager.detach(testClass);
entityManager.clear();
entityManager.close();
// 준영속
entityManager.remove(testClass);
//삭제
영속성 컨텍스트의 이점
1. 1차 캐시
영속성 컨텍스트는 내부적으로 1차 캐시가 존재합니다.
1차 캐시는 Map<Key(primary key), Value(Entity)> 형태로 저장합니다.
이렇게 되면, DB에 직접 조회를 요청하지 않아도 캐시에서 바로 조회가 가능하다는 이점이 있습니다.
존재하지 않는다면, DB에서 조회하여 캐시에 저장하고, 저장되어 있는 동안에는 빠른 조회가 가능합니다.
2. 동일성 보장
영속성 컨텍스트는 엔티티의 동일성을 보장합니다.
3. 쓰기 지연
transaction이 시작되는 시점부터 끝나는 시점까지 SQL을 모아 두고,
transaction이 종료되는 시점에 transaction.commit()이 호출됨과 동시에 모아둔 쿼리를 모두 보냅니다.
4. 변경 감지
위 예시에서 보듯 별도의 update 쿼리를 사용하지 않더라도 자동으로 commit시 db에 있는 데이터와 값 비교를 통해 변경을 감지합니다. 이를 Dirty Checking이라고 합니다.
'Spring&IntelliJ' 카테고리의 다른 글
| jdbcTemplate의 RowMapper<T>인터페이스에 대해서! (0) | 2023.12.19 |
|---|---|
| MyBatis란? (0) | 2023.10.24 |
| 템플릿 엔진? thymeleaf템플릿 엔진이란? JSP와 servlet의 다른점? (0) | 2023.09.30 |
| controller의 메서드의 매개변수로 오는 model객체란? (0) | 2023.09.30 |
| 디스패처 서블릿(Dispatcher servlet), Intercept, (0) | 2023.09.29 |


