출처: https://www.youtube.com/watch?v=QBISxH_KHog&list=PLOSNUO27qFbvzGd3yWbHISxHctPRKkctO&index=7
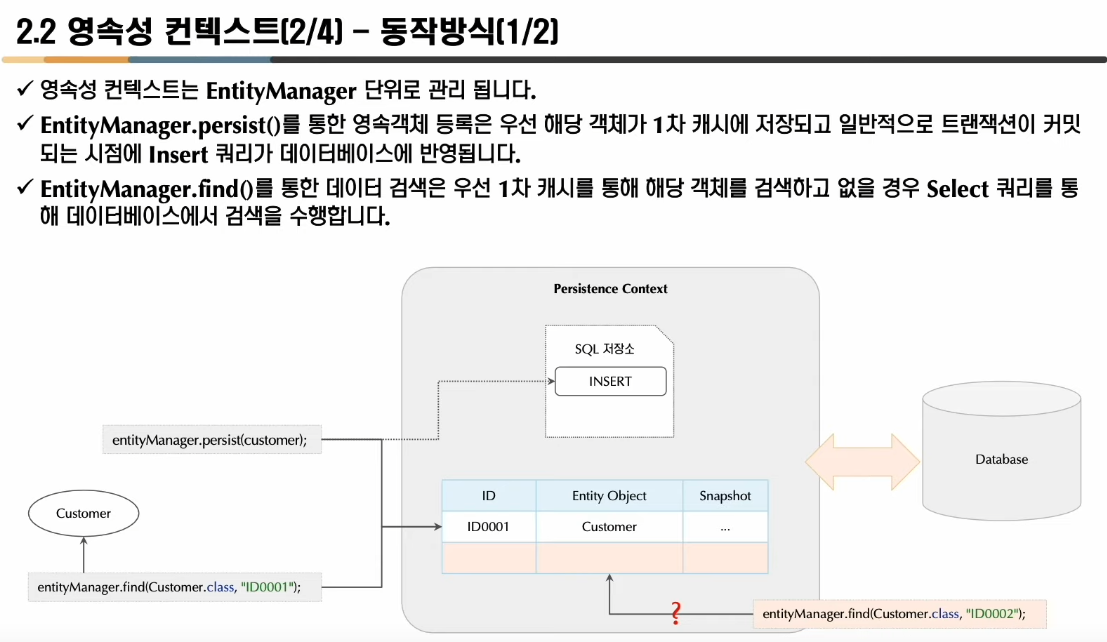
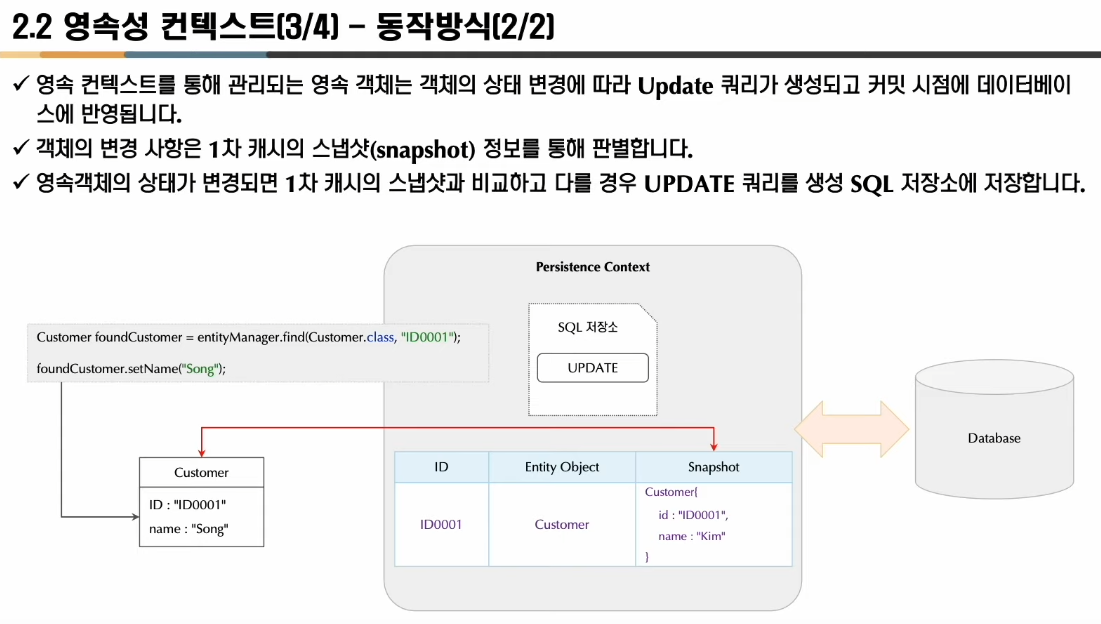
위의 Update쿼리가 생성되는 경우를 좀더 자세히 설명하면 이렇다. em.find(Customer.class, "ID0001");로 DB로부터데이터를 가지고온다(1차 캐쉬의 데이터를 가지고 온다고 생각해도 좋음) => 그렇게 정보를 가져온직후 PersistenceContext의 스냅샷을 찍는다. => setName("Song")을 통해 정보가 update되었다. => 찍어두었던 1차 캐시의 스냅샷정보와 현재 PersistenceContext의 상태를 비교한다.=> 만약에 다를 경우 update SQL쿼리를 생성하여 쓰기지연 SQL저장소에 저장한다. => commit혹은 flush시점에 DB로 쿼리를 날린다.

commit()하면 자동으로 flush()도 호출해줌. 즉 commit한다면 commit되기 이전에 flush됨.
위 설명대로 flush()를 하면 persistenceContext와 DB의 내용이 동기화 됩니다. 하지만 flush()한 후에 DB를 열어보면 데이터가 동기화되어 적절한 데이터로 변경되지는 않았음을 확인할 수 있습니다. DB에 육안으로 확인하여 반영이 됐다는 것은 이미 Commit하여 Rollback이 될 수 없는 상태를 의미합니다. 즉 flush를 통해 동기화 되었다고 해서 DB에 내용이 변경되는 것은 아님. 내용이 변경되었다는 것은 이미 Commit하여 Rollback이 될수 없는 상태임. (크흐... 정말 애매하다... 하지만 받아 들이자. 동기화가 곧 DB에서의 데이터 변경의 반영은 아니다!)
flush()의 기능은 DB와 Persistence Context간의 동기를 맞춘다(동기화) 라는 정도로 이해하시면 됩니다.
"flush()를 통해 동기화 하면 마치 DB에 반영되는 것과 같은 결과를 해당 트랜잭션 내에서 확인할 수 있다" ? 이게 무슨 말임? JPQL쿼리 실행을 통한 자동 플러시가 무엇인지를 아래 설명을 통해 이해하면 이해할 수 있다.
여러개의 쿼리를 조인하는 것같은 복잡한 쿼리는 단순 EntityManager의 메서드(예를들면 find())로 만들 수 없습니다(이것이 바로 DB쿼리 공부를 게을리 해서는 안되는 이유임). 그 때 사용되는 것이 JPQL과 같은 Query Language입니다.
JPQL의 예: Query query=em.createQuery("Select~~~~~~");
List<Customer>customers=query.getResultsList();

위와 같이 하나의 트랜잭션의 시작(tx.begin())과 끝(tx.commit())사이에 위와 같은 코드가 있다고 한다면 1,2행의 persist(cus01), persist(cus02)코드 때문에 쓰기지연SQL저장소에는 Insert~~와 같은 SQL쿼리가 대기하고 있을것이다. 왜냐하면 아직 commit되기 전이기 때문에. 그런데 이 상황에서 나는 위와 같은 JPQL를 통해 전체 고객들을 가져온다음에 customers라는 리스트에 담고 싶은 것입니다. 이때 JPQL쿼리를 실행한다면 실행되기 전 자동flush()가 일어나게 되어 쓰기지연 SQL저장소에 있었던 쿼리까지 모두 DB로 동기화되어 기존DB에 있었던 내용을 동기화하여 그 동기화된 내용의 데이터를 Persistence Context로 가져올수 있게 되는 것이다! 이것이 바로 위에서 말했던 "flush()를 통해 동기화 하면 마치 DB에 반영되는 것과 같은 결과를 해당 트랜잭션 내에서 확인할 수 있다"의 의미임.
'Spring&IntelliJ' 카테고리의 다른 글
| JPA. Sequence를 이용한 기본키 생성전략 (1) | 2024.01.04 |
|---|---|
| JPA 영속객체의 라이프사이클 (0) | 2024.01.02 |
| JPA 내부동작방식 (1) | 2024.01.02 |
| JPA DB에서 데이터 가져오기 (1) | 2024.01.02 |
| JPA (실습을 통해 익숙해 지는 JPA)EntityManager (0) | 2024.01.01 |



